
Task Introduction
Topic segmentation은 문서 내 유사한 의미를 가진 문장들을 단락으로 분리하는 태스크입니다. 문단 분리 태스크는 실생활에 어떤 도움을 줄 수 있을까요?
매일 수십개의 문서를 읽고 정보를 파악해야하는 직장인이 있다고 해봅시다. 하나의 문서가 단락 구분 없는 줄글이라면 문서 하나를 읽을 때 매우 큰 정신적 노동이 필요합니다. 사람은 하나의 주제를 가지고 이야기하는 단락을 이해하는데 큰 노력이 필요하지 않지만 여러 주제가 합쳐진 글을 읽을 때는 무의식적으로 정보를 유사한 것으로 분류하기에 그 만큼의 지식 노동이 추가로 요구되기 때문입니다.
만약 모델이 하나의 문서에서 의미적으로 유사한 단락을 나눠준다면 사람이 정보를 파악하기 훨씬 수월해질 것입니다. 이처럼 Topic(text) Segmentation 태스크는 문맥적으로 유사한 문장들을 단락으로 나누는 것을 학습 목표로 합니다.
Topic Segmentation에는 크게 2가지 방법론이 있습니다.
- Unsupervised
- 문장간 유사도를 계산해 유사도가 특정 값을 넘지 못하는 곳에서 문단을 나누는 방식. 학습시 label(문단이 나눠지는 위치)이 필요하지 않아 학습 과정이 필요 없다는 장점이 있음.
- Supervised
- 문단이 나눠지는 문장의 위치(index)가 label로 주어져 모델이 학습할 수 있음. Unsupervised보다 다양한 방식으로 모델을 학습할 수 있으며 성능이 우수하다는 장점이 있음.
오늘 리뷰할 논문은 Supervised Learning 방법론을 따릅니다.
Insights
이번 논문은 다음 2가지 시사점이 있습니다.
- 모델 아키텍처인 two-level 구조에 transformer 모델을 적용해 성능과 학습 속도를 향상함
- 기존 논문에는 문단을 분리하는 문장을 예측하는 classifier만 사용했지만 해당 논문은 문서 내 응집력를 함께 학습하는 multi-tasking을 수행함
Architecture
모델 아키텍처는 두 가지 특징이 있습니다. 이 두가지 특증을 중심으로 구조를 살펴보겠습니다.
- Two-level transformer
- Multi-task learning
Two-level transformer
- token-level transformer
첫번째 transformer 모델은 문서 내 k개 문장을 입력 받아 토큰으로 분리한 후 모델에 입력해 k개의 문장 encoding(sentence representation)을 생성합니다. 이를 논문에서는 token-level transformer라고 명칭합니다.
문서 내 문장 개수는 K개, 한 문장 내 토큰 개수는 T개라고 정의할 때, 모든 문장의 T가 고정된 값을 갖도록 합니다. 즉, 문장을 토크나이즈 할 때 토큰 개수가 T보다 적으면 패딩을 입력하고 반대로 많으면 잘라내 문장의 토큰 개수를 T로 맞춥니다.
토큰 기호: $t_j^i$ ($i\in {1, …, K}$, $j\in {0, …, T}$)
토큰 개수는 고정된 K 값이라고 설명했는데 토큰 기호를 보면 토큰 개수가 총 K+1개 입니다. 그 이유는 문장을 토크나이징 한 후 $t_0^i$ 토큰을 문장 맨 첫 토큰에 추가했기 때문입니다. $t_0^i$ 토큰은 i번 째 문장을 대표하는 값 입니다. 즉, transformer 모델을 통과한 $t_0^i$ 토큰을 i번째 문장의 encoding값으로 사용합니다.
총 (T+1x K)개의 토큰을 transformer모델에 입력합니다. Token encoding layer에서 각 토큰의 word embedding($d_e$ 차원 벡터)과 positional embedding($d_p$ 차원 벡터)이 concat되어 N개의 transformer encoder layer에 입력됩니다. 모델의 출력값으로 (T+1x K)개의 토큰 엠베딩이 출력됩니다. 그 중 문장의 맨 앞 토큰 ($t_0^i$) 엠베딩만 뽑아 총 K개의 sentence encoding 벡터를 생성합니다.
![]()
모델의 입력과 출력을 기호로 표현하면 위 수식과 같습니다. Transformer 모델의 출력값으로 ${tt_j^i}_0^T$ 토큰을 얻었고 sentence representation을 얻기 위해 문장 맨 앞 토큰 $tt_0^i$ T개를 뽑았습니다. 이제부터 sentence encoding의 기호는 다음과 같이 정의합니다.
문장 encoding 기호: $S_i$ = $tt_0^i$
- sentence-level transformer
첫 번째 모델이 문장을 벡터로 표현하는 역할을 했다면 두 번째 transformer 모델은 문장간 관계, 즉 문맥을 고려해 문장 벡터를 생성하는 역할을 합니다.
![]()
이렇게 생성된 문장 embedding은 ${ss_i}_0^K$로 표현됩니다. 문장은 K개 밖에 없는데 왜 문장 embedding은 K+1개 생성될까요? 이번 역시 문장 맨 앞에 <sss>라는 토큰을 추가해 문장 전체를 아우르는 문서 embedding을 얻습니다. $ss_0$ 문장 embedding이 바로 문서의 embedding이라고 할 수 있습니다.
Multi-task learning
- segmentation classifier
![]()
2개의 Transformer 모델을 거쳐 생성된 문장 embedding은(${ss_i}_0^K$) 1 layer feed forward neural network와 softmax를 통과합니다. 이는 이진 분류 모델로 문장이 단락을 구분하는 구분자인지 아닌지를 구분합니다.
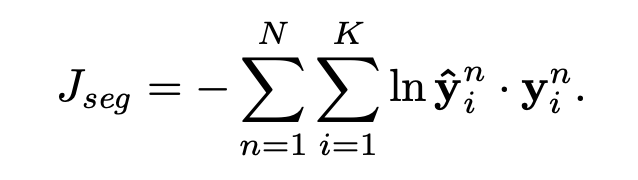
segmentation classifier의 목적 함수는 negative log-likelihood입니다. 여기서 N이란 한 배치(batch)에 존재하는 문서의 개수를 의미합니다. K개의 문장으로 구성된 N개의 문서의 negative log-likelihood의 값을 합해 한 배치의 loss를 계산합니다.
- coherence regressor
Transformer 모델에서 K+1의 문장 embedding을 생성했습니다. 그 중 K개의 문장 embedding은 앞서 본 segment classifier에 입력되고 남은 $ss_0$ 문서 embedding은 coherence regressor에 입력되 문서 내 문장들의 응집 정도를 예측합니다.
한 문서 내 문장들이 서로 비슷한 이야기를 한다면 응집도는 높을 것 입니다. 하지만 문장들 하나가 문맥에 벗어난 이야기를 한다면 문서의 응집도는 낮아질 것입니다. coherence regressor의 목적은 응집도가 높은 문서와 낮은 문서를 비교하며 상대적으로 높은 응집성을 가진 문서에 높은 응집성 점수를, 상대적으로 낮은 응집성을 가진 문서에는 낮은 응집성 점수를 주도록 모델을 학습합니다. 따라서 모델이 문서를 보고 응집도 점수를 예측할 수 있도록 말이죠.
논문에서는 대조 문서, 즉 낮은 응집성(corrupt)을 가진 문서를 생성하기 위해 두 가지 방법을 사용합니다. 문서 내 문장들의 순서를 바꾸거나(shuffling) 문장을 다른 문서의 문장과 바꿔치기 (replacing)를 합니다. 그 결과 ($ss_0$, $\overline{ss_0}$) 문서 embedding 쌍이 생성됩니다. $ss_0$는 응집성이 높은 문서의 embedding,$\overline{ss_0}$는 응집성이 낮은 문서의 embedding입니다.
![]()
![]()
문서 embedding쌍은 FFNN와 softmax를 통과해 응집도 점수를 생성합니다.
![]()
coherence regressor의 목적 함수는 contrastive margin loss로 $coh(S)$와 $coh(\overline{S})$의 차이가 margin 값인 $\delta_{coh}$보다 커지도록 모델을 학습한다.
Training Scheme
- Dataset
- 문서 내 문장 개수가
K를 초과할 경우, window size를K로 하고 stride를K/2로 해 문서를 새로 생성함. (논문에서는 이 문서를 snippet이라고 함) - Wiki-727K와 같은 written text data에 학습. label(문단 분리 문장 여부)은 위키피디아의 TOC(Table of Contents)를 사용함.
- 문서 내 문장 개수가
- Word Embedding
- 모델 앞 단의 word embedding은 학습시 업데이트 되지 않는 고정된 값임. 논문에서는 사전 학습된 FastText를 사용.
Evalutation Metrics
- $P_k$ Score
- $P_k$는 임의로 뽑은 k개 문장으로 구성된 snippet에서 모델이 단락 구분 예측을 틀렸을 확률을 의미함. 이 때, 모델이 snippet내에서 단락이 구분이 있는지만 없는지만 맞추면 정답으로 간주. 만약 한 snippet내에 단락 구분이 여러번 있었다면 모델이 그 중 몇개나 맞췄는지는 고려되지 않고 하나라도 맞추면 정답으로 간주한다는 한계점이 있음.
Results

이번 논문은 Koshorek et al. (2018) 논문의 모델 구조를 그대로 사용하되, Bi-LSTM을 transformer 모델로 변형해 큰 성능 향상을 보였습니다.
또한 multi-task learning 기법(CATS)이 단일 segmentation classfication (TLT-TS)모델보다 우수한 성능을 내는 것을 알 수 있습니다.
Implementation
논문의 코드는 github에 공개되어 있지만 다음과 같은 (지극히 개인적인) 한계점이 있습니다.
- tensorflow로 구현됨
- tensorflow 이전 버전으로 구현되어 현재 GPU와 cuda version이 맞지 않음
개인적으로 tensorflow 코드가 익숙하지 않아 이 참에 pytorch 최신 버전으로 코드를 재구현한다면 GPU로 쉽게 모델을 학습할 수 있을 것 같습니다. 코드 재구현이 끝나면 또 기록을 남기겠습니다.