
해당 게시물은 TheSequence에서 발간한 글 “‘ML Data’: The past, present and future”을 읽고 한국어로 번역 및 제 생각을 추가해 적은 글 임을 밝힙니다.
The Past (과거)
2010년대는 산업계에 빅데이터 열풍이 불었다. 대용량 데이터를 처리할 수 있는 Hadoop, MapReduce, Spark 같은 프레임워크가 활발히 사용되 여러 산업군에서 빅데이터를 저장 및 분석하는 시스템이 도입됐다. 동시에 머신 러닝과 딥러닝 프레임워크인 Tensorflow, Pytorch가 발전하면서 적은 코드로 쉽게 모델을 학습하고 배포하는 것이 쉬워졌다.
문제점: Data Sprawl
데이터의 양이 많아지면서 필연적으로 데이터 관리가 힘들어지는 문제가 발생했다. 데이터를 저장하는 위치나 방식이 일관적이지 않으면서 원하는 데이터를 빠르게 찾아보기가 힘들어졌다. 이처럼 생산성을 저하하는 데이터를 ROT라고 부른다.
- Redundant: 중복된 데이터가 여러개 저장됨
- Obsolete: 더 이상 유효하지 않은 데이터가 저장됨
- Trivial: 저장할 가치가 없는 데이터가 저장됨
The Present (현재)

딥러닝, 머신 러닝 모델 성능이 향상되면서 ML platform이 등장하기 시작했다. 여러 산업군에서 점점 더 다양한 모델로 문제를 풀기 시작하면서 여러 태스크를 푸는 모델이 여러 버전으로 만들어졌다. ML platform은 모델 학습과 평가 그리고 배포까지 한 곳에서 할 수 있도록 만들어준다. 예시로는 AWS Sagemaker, C3, DataRobot 등이 있다.
문제점: Data Bottleneck
다양한 태스크를 푸는 모델을 관리하다보니 모델 별로 데이터를 저장해야 한다. 이전에 살펴봤던 data sprawl 문제와 유사하게 데이터가 중복되어 저장되기도 하고 여러 위치에 산재되어 저장되고 관리되다 보니 운영비가 많이 나가게 된다. 이를 data fan-out 문제라고도 하는데 하나의 모델이 여러 데이터 베이스에서 데이터를 찾아 학습 및 추론하는 현상을 말한다. 이는 마이크로 서비스에서 지양하는 방식 중 하나로 여러 데이터 베이스에 쿼리를 날리게 됨으로 시간 지연을 초래한다. 이처럼 오늘날에는 ML platform의 발전으로 모델을 관리하기는 쉬워졌지만 여전히 모델 별 데이터 관리가 힘들다는 문제는 남아 있다.
해결책: Feature Store
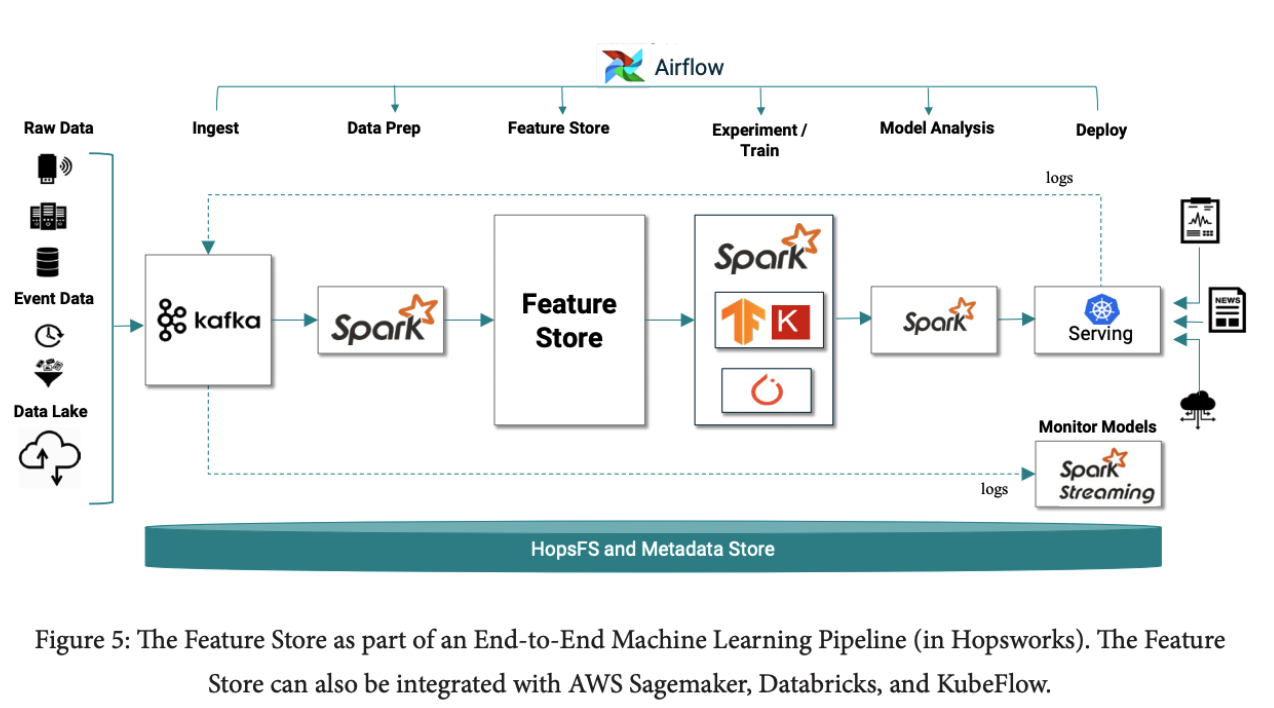
머신 러닝, 딥 러닝 파이프 라인을 제공해주는 플랫폼에서 feature store라는 기능을 본 적이 있을 것이다. 오늘날 대부분의 데이터는 embedding (즉, 고차원의 벡터)으로 표현할 수 있고 또한 embedding을 잘 학습한 pretrained 모델을 언제 어디서든 다운 받아 사용할 수 있다. 데이터를 embedding으로 변환한 후 feature store에 저장할 수 있는데 이러면 매번 데이터를 embedding으로 변환할 필요 없이 feature store에서 원하는 embedding을 찾아 사용하면 되 데이터 중복을 피할 수 있다. AWS Sagemaker, Databrick, Hopsworks 같은 플랫폼이 feature store 기능을 제공한다.
The Future (미래)

과거부터 지금까지 주목할 만한 특징을 살펴보면 다음과 같다.
- Pre-trained model의 상용화
- ML Framework의 발전
- 데이터 관리 방식의 향상
문제점: Low Data Quality
지금까지는 데이터의 질보다는 양을 우선시 했다. 즉, 적지만 질이 좋은 데이터보다 질이 낮지만 많은 데이터를 선택했다. 하지만 앞으로는 데이터의 질이 양보다 더 중요해진다.
오늘날 모델 학습의 문제점으로는 다음과 같은 점을 들 수 있다.
- 모델과 데이터의 적합성에 대해 고려를 적게 함
- 잘못 레이블링된 학습 데이터를 다시 고치는데 시간이 많이 소요됨
- 어떤 학습 데이터가 모델의 성능을 저하시키는지 발견하기 어려움
- 서비스 중인 모델이 재학습이 필요한 시기를 자동으로 탐지하기 어려움
해결책
우버(Uber)에서는 위의 문제점을 해결하기 위해 다음과 같은 기능을 개발했다고 한다.
- 모델이 어떤 데이터 유형에 오류를 냈는지 자동으로 탐지
- 만약 학습 데이터가 모델 성능 저하를 일으키면 자동으로 탐지하고 데이터를 걸러내거나 고침
- 특정 quality 기준을 미치지 못한 파이프라인 (모델)을 서비스에서 배제함
- 모델별로 좋은 피처를 자동으로 찾아줌
도래하는 Data-centric 시대에 AI 엔지니어 및 리서처가 풀어야 할 숙제는 다음과 같다.
- 데이터가 모델에게 어떤 영향을 주는지 알아내고 대응할 수 있어야 한다. 그리고 이 과정을 자동화할 수 있어야 한다.
- 데이터를 개선할 수 있어야 한다.
- 어떤 데이터와 어떤 레이블을 사용할 지 결정할 수 있어야 한다.
- 어떤 데이터를 레이블링 할 지 판단할 수 있어야 한다.
- 데이터 내에 내재된 bias를 찾을 수 있어야 한다.
- 새로운 유형의 데이터 유입을 찾아내고 모델을 재 학습할 수 있어야 한다.