Contents
Bert
[용어] Bert는 입력된 문장을 단어(word)로 구분하지 않는다. 대신 Wordpiece tokenizer로 생성된 subword로 구분한다. 예를 들어 “이 원피스 예뻐요.”라는 문장이 입력됐을 때 wordpiece tokenizer는 [“이”, “원피스”, “예뻐”, “#요”]라는 subword를 생성하며 각 subword가 Bert 모델의 인풋으로 들어간다. 따라서 이 포스팅에서는 모델의 인풋을 “단어”라는 용어 대신
subword라고 칭하겠다.
Bert 모델의 2가지 대표적인 특징은 transfer learning(전이학습)을 한다는 점과 transformer(auto-encoder) model이라는 점이다.
transfer model은 pre-training과 fine-tuning 단계가 있다. Pre-training은 인풋 sequence에서 mask된 subword를 찾는 (language model) semi-supervised 학습을 대용량 데이터와 깊은 네트워크로 오랜 시간 학습해 학습한다. Fine-tuning은 pre-trained 모델의 마지막 레이어를 풀고자하는 task에 맞게 변형해 supervised 학습하는 모델이다. (참고: ensemble, distillation)
transformer는 Attention is all you need 논문에서 제안한 네트워크 구조다. 기존 encoder-decoder모델은 학습이 한 방향으로 진행되는 auto-regressive한 RNN 구조로 이루어졌다. 이와 달리 transformer는 입력 sequence의 모든 토큰을 동시에 학습하는 attention 구조로만 이루어진 encoder-decoder이다.
![]()
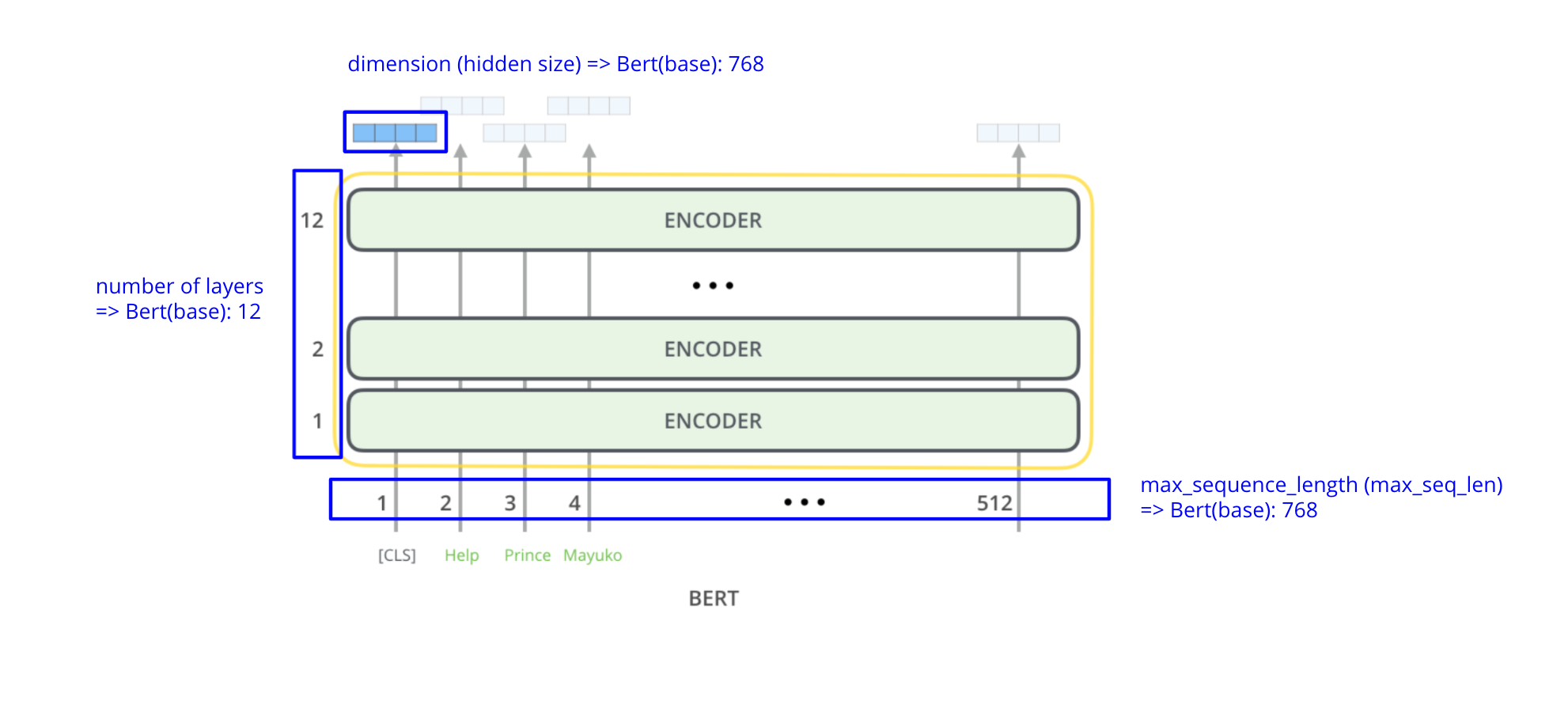
Bert는 transformer의 encoder를 여려겹 쌓아올린(stacked) 모델이다. Transformer의 encoder 구조는 다음과 같다.
- Stack of layers (N=6)
- Sub-layer1:
Multi-head self-attention- residual connection
- layer normalization
- Sub-layer2:
Fully-connected Feed-forword- residual connection
- layer normalization
- Sub-layer1:
Bert 모델의 파라미터는 다음과 같다.
| BERT Model | # layers | dimension (=hidden size) | # attention heads | total # params |
|---|---|---|---|---|
| BERT (base) | 12 | 768 | 12 | 110M |
| BERT (large) | 24 | 1024 | 16 | 340M |
- number of layers
- encoder layer의 개수
- dimension (hidden size)
- subword embedding(vector)의 차원
- 모든 layer의 input, output dimension은 동일하게 유지된다.
- max sequence len
- 입력 sequence의 최대 subword 개수
- 보통 training data의 가장 긴 문장의 subword를 개수로 설정한다.
- number of attention heads
- attention의 head 개수. multi-head attention은 head 개수만큼의 attention이 병렬 처리된다.
그렇다면 Bert 모델의 핵심인 attention이란 무엇일까? 즉, multi-head self-attention layer에서는 어떤 값이 계산되는 것일까?
Attention이 등장하기 이전까지 seq-to-seq 모델에는 RNN, LSTM과 같은 recurrent 모델이 사용됐다. 하지만 recurrent 모델은 긴 문장이 인풋으로 들어올 때 hidden state(weight)값이 제대로 학습되지 않는다는 문제가 있다. 예를 들어 “뽀로로는 노는게 제일 좋아”라는 문장이 있을 때, 첫번째 단어인 “뽀로로”의 weight(w0)가 마지막 단어인 “좋아”의 weight(w3)를 계산하는데 거의 영향을 미치지 않는 문제가 발생한다.(수정 필요)
Attention은 모든 input 단어들의 관련도 점수(attention score)를 계산하여 관련도 점수가 높은 단어는 많이, 점수가 낮은 단어는 적게 고려한다. 즉, output과 관련된 input의 weight만 고려한다.
서두에 Transformer는 recurrent 모델을 사용하지 않고 attention으로만 이루어진 encoder-decoder(=seq2seq) 모델이라고 설명했다. Transformer의 또 다른 큰 특징은 attention이 행렬 연산이기 때문에 병렬 처리 학습이 가능하다는 점이다.
Attention은 4가지 과정을 거쳐 계산된다.
- subword별로 Query, Key, Value 백터 생성
- subword간(pair-wise)의 Score 계산
- Score를 normalize(scaling) 함
- Score에 softmax 함수를 적용해 [0,1] 사이의 확률 값으로 만듦
- 모든 subword에 대해 4번 값과 Value 백터 값을 곱한다. 하나의 attention 값을 만들기 위해 subword의 score을 모두 더한다.
사용되는 벡터의 종류는 총 3가지이다.
- Q (query)
- K (key)
- V (value)
여기서 관련도 점수(attention score)는 Q와 K의 값으로 구한다.
Attention score는 “Scaled dot product of Q,K”라고 하는데 이 점수를 softmax함수에 넣어 0과 1사이의 확률값으로 만든다. 이 attention score는 V(value)의 weight 값으로 사용되 V의 가중치를 결정한다.
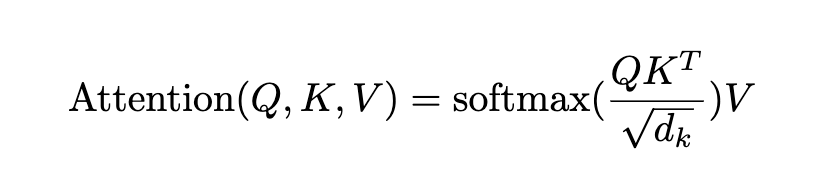
(…TODO: more about attention…)
Albert
Albert는 기존 Bert 모델의 2가지 단점을 개선했다. 먼저 모델의 파라미터 수를 줄이고 layer간에 파라미터를 공유하도록 구조를 변형해 모델 크기를 줄였다. 또한 Pre-training의 task 중 하나였던 Next Sentence Prediction의 학습 방법을 바꿔 문장 사이의 관계 학습하는 task (ex. MNLI)에서 기존 보다 높은 성능을 보였다.
Bert(base) 모델의 parameter 개수는 1억개다. 만약 12G 용량의 GPU 1대가 있다고 가정했을 때, Out-of-memory에러가 나지 않는 최대 batch size는 다음과 같다.
| BERT Model | batch size | sequence length |
|---|---|---|
| BERT (base) | 64 | 64 |
| BERT (base) | 32 | 128 |
| BERT (base) | 16 | 256 |
| BERT (base) | 14 | 320 |
| BERT (base) | 12 | 384 |
| BERT (base) | 6 | 512 |
Bert(base) 모델의 sequence length가 512인데 GPU 1대로 fine-tuning을 한다고 할 때 batch size는 최대 6밖에 설정할 수 없다.
따라서 일반적인 하드웨어 자원으로는 Bert 모델을 완벽하게 사용하기 힘들다.
한글 데이터셋을 이용한 사전 학습 Tutorial
tokenization
-
형태소분석 한국어는 교착어이다. 교착어란 한 단어에 어근과 접사가 붙어있는 형태를 말하는데 어근은 의미를 나타내는 역할이고 접사는 시제, 높임 처럼 문법적인 기능을 한다. 따라서 한국어는 단순히 문장을 공백으로 나누는 대신 (ex.
"오늘은 비가 옵니다. 어제는 비가 왔었나요?".split(" ")) 형태소 단위까지 분리해줘야 한다.
형태소 분석을 지원하는 파이썬 패키지는 다양하다. 나는 Mecab 형태소 분석기를 사용했다. Mecab 사용법 포스팅 -
subword tokenizing Bert 학습에 중요한 요소 중 하나는 vocab이다. Bert는 사전 학습에서 Masked Language Model 문제를 푸는데 masking된 토큰이 실제로 어떤 값인지 맞추는 분류 문제다. 보통 vocab은 30,000개로 구성되는데 MLM은 이 30,000개의 vocab 중 1개를 맞추는 문제라고 할 수 있다. 따라서 vocab size가 너무 커버리면 제대로 학습이 안될 수 있고 너무 작으면 out-of-vocabulary 문제가 발생한다.
Out-of-vocabulary란 vocab에 없는 token을 말한다. vocab에 없는 token은 “
subword tokenizing에는 word piece tokenizing, sentence piece tokenizing, bype-pair encoding등이 있다. subword tokenizing은 먼저 단어를 character 단위로 쪼갠 후 character들의 쌍을 만들어간다. subword toeknizing의 알고리즘을 한 마디로 표현하면 “자주 나오는 character 쌍을 찾으면 하나의 토큰으로 묶어 주자!” 이다. 반대로 어떤 character 쌍이 등장하는 빈도가 적으면 character들은 묶이지 않고 각자 개별적인 토큰이 된다.
형태소 분석 후 subword tokenizing을 하면, 띄어 쓰기 오류때문에 형태소 분석이 불가능했던 단어도 tokenizing이 가능해진다는 점이다.

pre-training
한글 데이터에 Albert 모델을 pre-training하고 싶다! official albert github에서 소스 코드를 받아와 직접 pre-training 해보자!
- create_pretraining_data
사전 학습을 하기 위해서는 내가 가지고 있는 데이터(corpus)를
tfrecord로 변형해야 한다.
소스 코드는 https://github.com/google-research/albert/blob/master/create_pretraining_data.py에 있다. 여러 문장이 공백으로 분리된 문서(.txt)를 읽어들여 하나의 sequence로 만들고 tokenizing을 한다. 그 후에는 token을 token_id로 변형하고 masking과 next sentence를 지정해줘 TrainingInstance 객체에 저장한다.
1,500,000개의 문장(문서를 40번 복제하기 때문에 실제로는 60M의 문장)을 TrainingInstance로 만드는데 5시간 정도가 소요됐다.
시간을 단축하기 위해 소스 코드에 Multi-processing을 추가했다.
- multi-processing
create_instances_from_document()함수를 multi-process로 실행하는 코드를 추가- functools.partial()
- 함수의 특정 인자가 freeze된 새로운 함수(partial object)를 생성해 반환.
- multiprocessing.Pool.starmap()
Pool.map()과 유사한 기능이지만 함수에 multiple argument를 넣을 수 있다.Pool.starmap(func, [(1,2),(3,4)])<=>[func(1,2), func(3,4)]
# input file을 가공해 TrainingInstance로 만드는 함수
def create_training_instances(input_files, tokenizer, max_seq_length,
dupe_factor, short_seq_prob, masked_lm_prob,
max_predictions_per_seq, rng):
"""Create `TrainingInstance`s from raw text."""
all_documents = [[]]
# Input file format:
# (1) One sentence per line. These should ideally be actual sentences, not
# entire paragraphs or arbitrary spans of text. (Because we use the
# sentence boundaries for the "next sentence prediction" task).
# (2) Blank lines between documents. Document boundaries are needed so
# that the "next sentence prediction" task doesn't span between documents.
for input_file in input_files:
with tf.gfile.GFile(input_file, FLAGS.input_file_mode) as reader:
while True:
line = reader.readline()
if not FLAGS.spm_model_file:
line = tokenization.convert_to_unicode(line)
if not line:
break
if FLAGS.spm_model_file:
line = tokenization.preprocess_text(line, lower=FLAGS.do_lower_case)
else:
line = line.strip()
# Empty lines are used as document delimiters
if not line:
all_documents.append([])
tokens = tokenizer.tokenize(line)
if tokens:
all_documents[-1].append(tokens)
# Remove empty documents
all_documents = [x for x in all_documents if x]
rng.shuffle(all_documents)
vocab_words = list(tokenizer.vocab.keys())
## multi-processing added ##
instances = []
for _ in range(dupe_factor):
instances.extend(
run_multiprocess(all_documents, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng))
############################
rng.shuffle(instances)
return instances
def run_multiprocess(
all_documents, max_seq_length, short_seq_prob,
masked_lm_prob, max_predictions_per_seq, vocab_words, rng):
# create_instances_from_document 함수를 multi-process
func = partial(create_instances_from_document,
all_documents = all_documents, max_seq_length=max_seq_length,
short_seq_prob=short_seq_prob, masked_lm_prob=masked_lm_prob, max_predictions_per_seq=max_predictions_per_seq,
vocab_words=vocab_words, rng=rng)
with Pool(cpu_count()-10) as pool:
listed_res = pool.starmap(func, [(idx,) for idx in range(len(all_documents))])
flattened_res = [token for tokens in listed_res for token in tokens]
return flattened_res
- pretrain
pretraining results
fine-tuning
Application
word embedding
Reference
BERT official github
Illustrated Bert
Illustrated Transformer
Illustrated Seq2Seq model with attention
BERT word encoding tutorial
BERT encoder decoder dissect
BERT architecture parameters calculated
BERT 한글 설명: 톺아보기