Elastic Search
ElasticSearch는 Lucene 라이브러리 기반의 검색 엔진이다.
DB-EnginesRanking에 따르면 ElasticSearch는 현재 업계에서 가장 인기있는 검색 엔진이라고 한다.
이 번 포스팅에서는 ElasticSearch의 개념, 용어, 특징을 알아보고 설치 후 실습을 진행해보도록 한다.
개념 및 특징
- Full-text serach in real time
- 다른 DB와 달리 ElasticSearch는 텍스트 전문에서 검색이 빠르다. inverted index라는 색인 작업으로 데이터를 저장하기 때문에 텍스트 검색이 빠르다.
- Distributed data
- Multitenant-capable
- 여기서 tenant는 Index, 즉 관계형 데이터베이스의 개념으로 보면 데이터베이스르 의미한다. ElasticSearch는 관계형 데이터베이스와 개념이 유사하지만 Field 값만 동일하다면 서로 다른 Index에서 동시에 조회할 수 있다.
- Schema-free JSON documents
- 스키마가 없이 json 포멧으로 데이터 CRUD(CreateReadUpdateDelete) 작업이 가능하다.
- HTTP web interface
- RESTful API 통신을 지원한다.
- Data analysis plugin avaialbe
- Hadoop, SQL 플러그인을 지원해 데이터 분석을 쉽게 할 수 있다.
구조(Architecture) 및 주요 용어
Logical Architecture

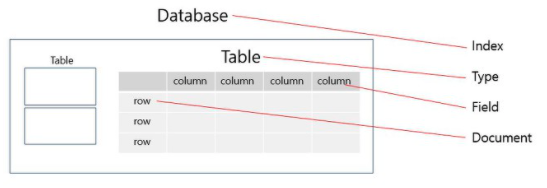
| Relational DB | ElasticSearch |
|---|---|
| Database | Index |
| Table | Type |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | Query DSL |
- Document
- Document란 JSON object로 Elasticsearch의 기본 저장 단위이다. 관계형 데이터베이스에서 테이블 한 행의 데이터와 의미가 유사하다.
- 내가 어떤 서비스를 운영한다고 했을 때, 서비스에 회원가입한 유저 데이터(이름, 나이, 성별, 등록일자)를 담고 있는 document는 다음과 같다. underscore(
_)로 시작하는 key는 document의 메타데이터이다.
{
"_id" : 3,
"_type" : ["your index type"],
"_index" : ["your index name"],
"_source" : {
"name" : "Christina",
"age" : 26,
"gender" : "female",
"date-of-enroll" : "2021-01-01"
}
}
- Field
- 위 예제에서 볼 수 있듯이 document는 key와 value 쌍으로 구성된다. 여기서 하나의 key, value 쌍이 Field이다. Field는 데이터의 가장 작은 단위이다. Field는 고유의 데이터 구조(data structure)와 값을 갖는데 Elasticsearch가 빠른 탐색 속도를 갖는 이유가 이 데이터구조에 있다.
- 데이터 구조 종류는 다음과 같다.
- core datatypes
- strings
- numbers
- dates
- booleans
- complex datatypes
- object
- nested
- geo datatypes
- get_point
- geo_shape
- specialized datatypes
- core datatypes
- Index
- Index는 Document의 논리적 분할로, Elasticsearch의 가장 큰 데이터 단위이다. 관계형 데이터베이스의 데이터베이스와 개념이 유사하다.
- 위 예시를 다시 가져와보면, 내가 만든 서비스를 사용하는 사용자에 대한 데이터는 사용자의 회원 가입 정보 (위 예시) 외에도 사용자 로그 정보도 있을 수 있다. 이처럼 사용자에 관련된 모든 documents가 하나의 index에 저장될 수 있다.
- 서비스에는 비단 사용자의 데이터만 있는 것이 아니라 가격 정보, 상품 정보 등 다양한 종류의 데이터가 있다. 이 데이터는 Elasticsearch내에 가격 documents를 저장하고 있는 index, 상품 documents를 저장하고 있는 index 등으로 정의될 수 있다.
Physical Architecture

| Relational DB | ElasticSearch | |
|---|---|---|
| Physical Partition | Shard |
- Shard & Replica
- 샤딩(Sharding)은 horizontal partitioning 또는 scale out 방법 중 하나인데, 같은 스키마를 가진 하나의 테이블을 행으로 나누어 저장하는 데이터 분산 저장 방식을 의미한다. ElasticSearch에서는 Index를 여러 shard로 쪼개는 방식으로 데이터를 분산 저장한다. Shard는 기본적으로 한 개 존재하며, 클러스터 내 샤드 개수를 튜닝하여 검색 성능을 향상시킬 수 있다.

- 노드를 손실했을 때 데이터의 신뢰성을 위해 샤드를 복제한 복제본을 Replica라고 한다. Replica와 Shard는 서로 다른 노드에 위치한다.
- Node
- Node는 HTTP 통신으로 요청 및 응답을 한다. 같은 Cluster내의 여러 Node들은 통신이 가능하기 때문에 요청이 들어왔을 때, Node간 통신을 통해 요청에 응답할 수 있는 Node에 요청을 넘겨준다.
- Node Rules
- master-eligible node
- Cluster 관리 노드
- data node
- 데이터 저장 및 CRUD 작업 수행 노드
- ingest node
- 데이터 인덱싱 등 사전 처리 파이프라인 구축 노드
- master-eligible node
- Cluster
- ElasticSearch에서 가장 큰 시스템 단위를 의미하며 Cluster는 하나 이상의 노드로 이루어진 노드 집합이다. 여러대의 서버가 하나의 Cluster를 구성할 수도, 한 서버에 여러 Cluster가 존재할 수도 있다.
특징
데이터를 저장하고 검색하는 작업은 관계형 데이터베이스인 MySQL로도 충분할 것 같은데, 왜 굳이 ElasticSearch같은 검색 엔진을 사용할까?
ElasticSearch의 특징을 살펴보면 그 이유를 알 수 있다.
역색인 (Inverted Index)

관계형 데이터베이스는 다음과 같이 색인(indexing)한다.
| DocId | Text |
|---|---|
| 0 | “The quick brown fox jumps over the lazy dog” |
| 1 | “Fast jumping rabbits” |
역색인(Inverted Indexing)은 문장의 단어들을 분리해 검색어 사전을 만든다.
| Token | DocId |
|---|---|
| quick | 0, 1 |
| brown | 0 |
| fox | 0 |
| jump | 0, 1 |
| … | … |
자연여처리 (NLP)
- 대소문자 변환
- 불용어 제거
- 형태소 분석 (ex. jumping = jumps)
- 동의어 처리 (ex. quick = fast)
설치
실습
Reference
ElasticSearch 공식 문서 10-elasticsearch-concepts database-shard d2 slideshare 1 elastic.co slidshare 2