Problem
이 포스팅은 어떤 문제 상황을 해결할까?
Python은 느리다!
파이썬은 single core, 즉 하나의 CPU만 사용하기 때문에 대용량 데이터를 다룰때 처리 속도가 느리다는 문제가 생긴다. 파이썬 자체는 싱글 코어에 램으로 작동하지만 파이썬의 몇몇 패키지는 멀티 코어를 사용할 수 있게 한다. 대표적이 예가 numpy 패키지로 이는 C 언어로 바인딩되어있기 때문에 multiple core, 또는 GPU를 사용할 수 있다. 이 포스팅에서는 파이썬에서 다중 코어를 사용해 데이터 병럴 처리를 하는 방법을 소개하려고 한다. 그 중에서도 대용량 데이터를 처리할 수 있는 dask 패키지를 소개한다.
Pandas는 데이터를 가공 패키지로 다양한 데이터 처리 함수를 제공해 데이터 가공에 흔히 사용되지만, 10GB가 넘어가는 데이터를 처리하는데는 속도가 느려진다는 단점이 있다. dask는 판다스보다 대용량 데이터를 더 빠르게 처리할 수 있으며, 컴퓨터의 램보다 더 큰 용량의 데이터도 로드할 수 있다.
Goal
- dask를 이해한다.
- python으로 기본적인 dask 튜토리얼을 진행한다.
Dask Explained
dask란?
dask는 python에서 멀티 코어로 병렬 처리를 가능하게 하는 패키지다. dask의 주요 특징은 다음과 같다.
- 작업 스케줄링 (dynamic task scheduling)
- 여러개의 코어를 사용하여 분산 처리
- 메모리 사이즈보다 큰 용량의 데이터도 처리 가능
- pandas, numpy와 사용 방법이 유사
dask cluster
dask는 dask cluster로 데이터를 병렬 처리한다.
cluster란 CPU, 메모리 관리 및 작업을 분배하는 역할을 하는 스케줄러(scheduler)인 Head와 실제 작업을 수행하는 여러 Node로 구성된다. 각 node들은 데이터 저장 공간(Storage)을 공유하고 있다.
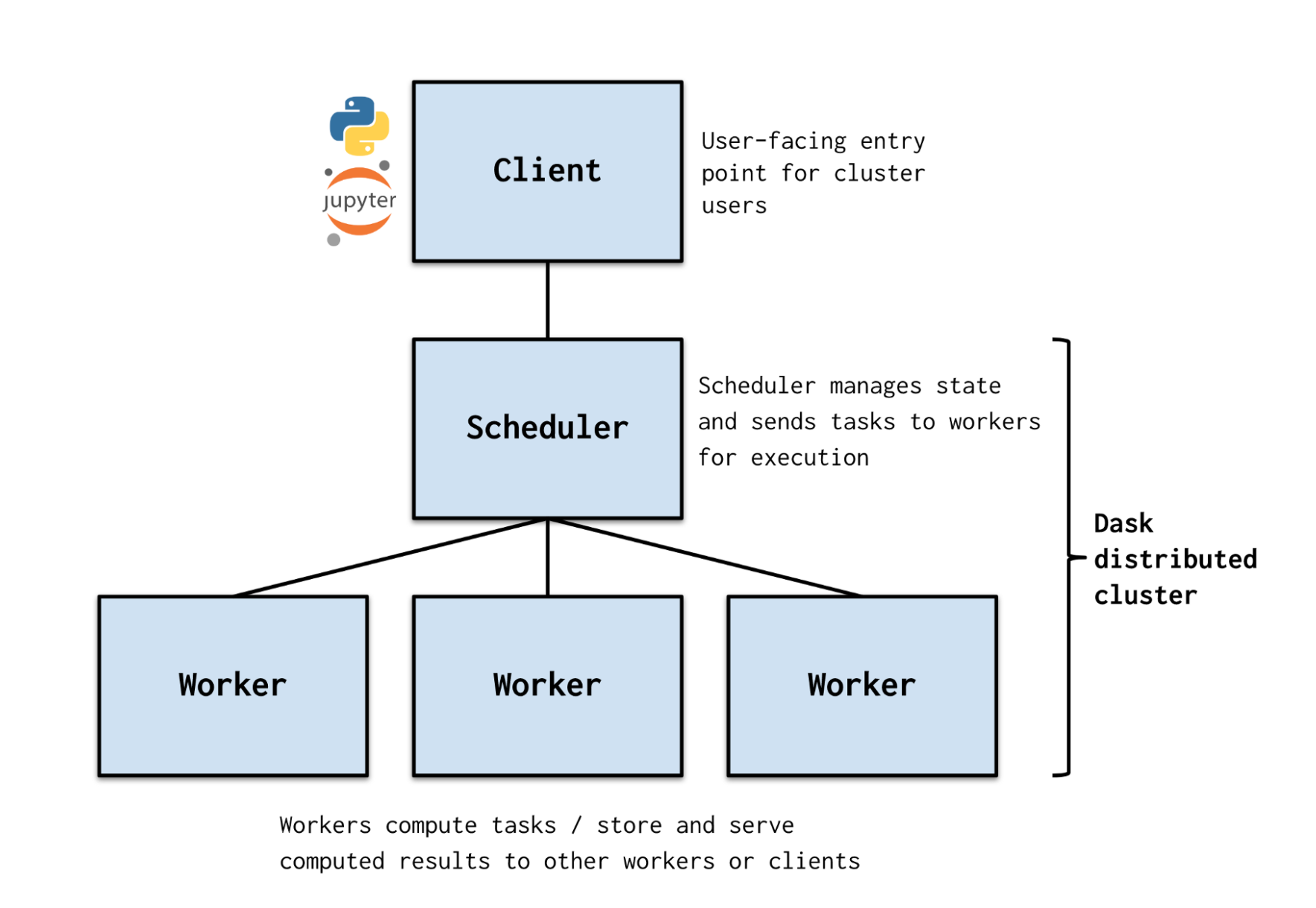 파이썬에서 데이터를 처리하는 사용자가 dask로 데이터 처리를 요청하면 (Client), Scheduler가 이 요청을 받아 여러 개의 하위 작업으로 나누어 worker에게 분배한다. Worker는 분할된 작업을 수행하고, 수행하는 과정에서 worker간 커뮤니케이션이 이루어진다.
파이썬에서 데이터를 처리하는 사용자가 dask로 데이터 처리를 요청하면 (Client), Scheduler가 이 요청을 받아 여러 개의 하위 작업으로 나누어 worker에게 분배한다. Worker는 분할된 작업을 수행하고, 수행하는 과정에서 worker간 커뮤니케이션이 이루어진다.
dask collections
dask의 자료구조?
Dask는 Bag, Array, Dataframe collection을 제공하며 이는 각각 파이썬의 list, numpy, pandas와 유사하다. 하지만 dask의 collection은 대용량 데이터를 병렬 처리할 수 있다는 장점이 있다.
dask schedulers
dask의 처리방식?
Dask는 작업 스케줄링(task scheduler)을 통해 task graph의 작업을 병렬로 처리한다.
- single machine scheduler
dask가 제공하는 default scheduler로, single mahcine에서 쓰레드(thread)나 프로세스(process)를 사용해 병렬 처리를 수행함. 사용자가 직접 설정할 필요가 없다는 장점이 있음.
- distributed scheduler
비동기식(asynchronous) 병렬 처리 가능. 또한 처리 과정을 대시보드로 볼 수 있음. (port 8787)

Spark와 차이점은?
Spark 역시 데이터를 병렬로 처리할 수 있는 분산 컴퓨팅 엔진이다. 그렇다면 dask과 spark보다 뛰어난 점은 무엇일까?
-
dask는 python 언어로 쓰였기 때문에 python 라이브러리 (pandas, numpy)와 함께 쓰기 좋다. 특히 dask dataframe과 같은 collection은 pandas API와 메모리 모델을 사용해 구현했다.
-
light-weight
반대로, Spark는 보다 더 안정적이고 지원 서비스가 다양하기 때문에 SQL 언어와 친숙하다면 Spark를 사용하는 게 좋다.
물론 Kubernetes 같은 자원 관리 프로그램을 사용해, 하나의 클러스터에서 Spark와 Dask를 같이 쓰는 방법도 있다.
자세한 설명은 dask documentation 을 참고하자.
Tutorial: Basic
- Dask 패키지 설치
pip install dask[complete] # install everything
- Cluster 생성 후 Client와 연결
from dask.distributed import LocalCluster, Client
cluster = LocalCluster()
client = Client(cluster)
- 스케줄러의 정보 확인
client.scheduler_info()
대시보드의 포트 번호 확인 가능
- dask collections: array

import dask.array as da
x = da.random.random((10000,10000), chunks=(1000,1000))
x

dask array는 작은 numpy ndarray들의 모음이다. 10K10K의 매트릭스를 1K1k 청크 100개로 쪼갠다.
- dask collections: dataframe
import dask.dataframe as dd
dask.dataframe은 긴 row를 가진 데이터프레임을 처리하는데 효과적이다.
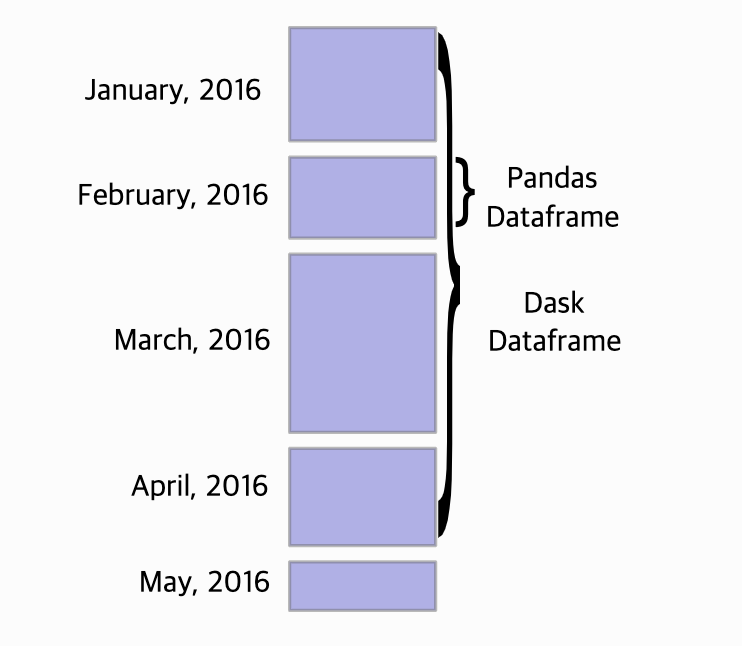
dask.dataframe은 pandas dataframe들이 row-wise하게 연결되어있으며, 실제 데이터프레임을 처리할 때는 row단위로 잘라서 병렬 처리한다. 따라서 pandas로 처리하기 힘든 긴(many rows) 데이터가 있다면, dask를 사용하자.
Tutorial: Advanced
여기서는 1,300만 row를 가진 데이터프레임을 pandas와 dask로 불러와 처리 속도를 비교해보고자 한다.
- 데이터 로드
dask의 데이터 로드 속도는 pandas보다 1000배 빠르다.
이런 속도 차이가 가능한 이유는 dask는 데이터를 로드할 때 실제 연산을 수행하지 않기 때문이다.
Lazy Evaluation은 어떤 값이 실제로 쓰일 때까지 계산을 미루는 동작 방식이다.
dask는 lazy evaluation으로 작동하기 때문에 compute() 메소드를 호출하지 전까지 데이터가 메모리에 올라가지 않는다.
import pandas as pd
import numpy as np
import dask.dataframe as dd
import dask.bag as db
import json
timeit -r 2 -n 1 pd.read_csv("df4pid_r_date.tsv", sep = '\t')
# 17.4 s ± 134 ms per loop (mean ± std. dev. of 2 runs, 1 loop each)
timeit -r 2 -n 1 dd.read_csv("df4pid_r_date.tsv", sep = '\t')
# 15.9 ms ± 1.88 ms per loop (mean ± std. dev. of 2 runs, 1 loop each)
dask는 데이터를 로드할 때 실제 값이 아닌 그 구조만 가져온다.
데이터프레임은 아래 그림처럼 값이 아닌 자료형만 확인할 수 있다.
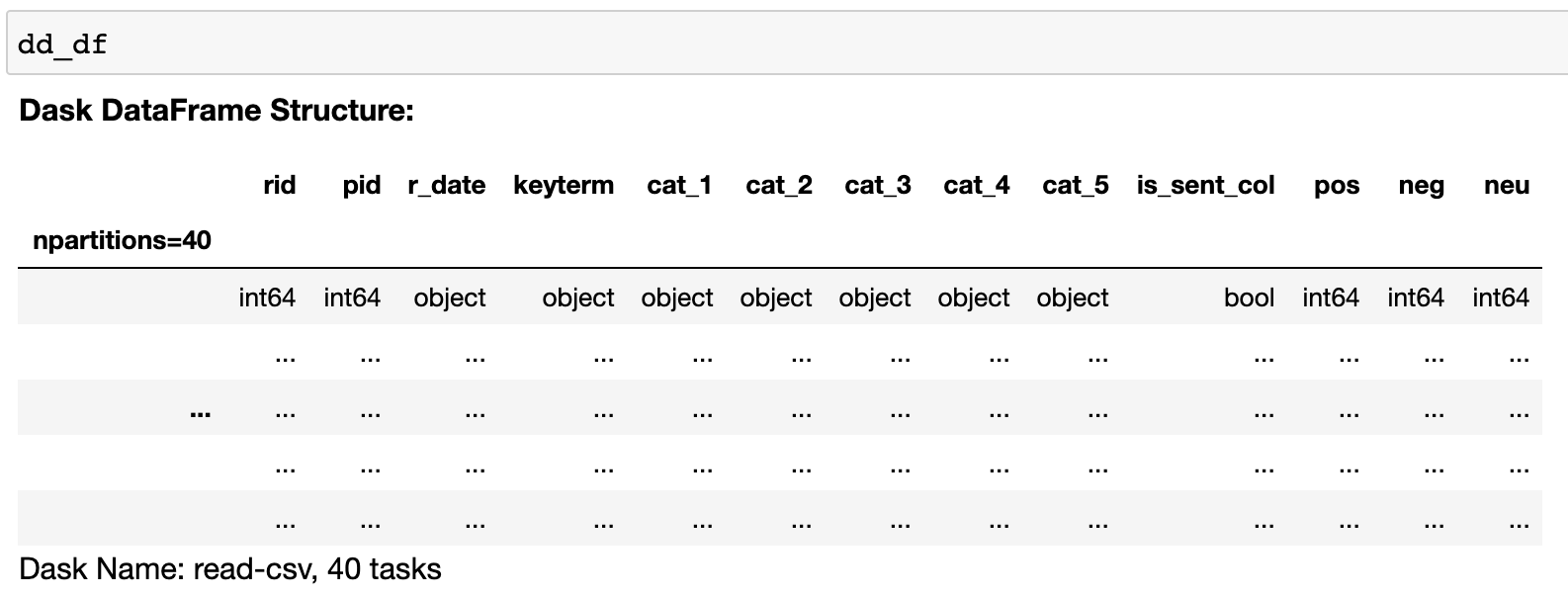
- 데이터 확인
dask는 데이터프레임의 뼈대만 로드하기 때문에 실제 값은 계산이 필요한 순간에 가져온다. 데이터를 확인하기위해서도 df.head()와 같이 계산식을 넣어줘야 한다.
timeit -r 5 -n 1 pd_df.head()
#149 µs ± 75.8 µs per loop (mean ± std. dev. of 5 runs, 1 loop each)
timeit -r 5 -n 1 dd_df.head()
#563 ms ± 28.3 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
결론적으로보면, 데이터프레임 계산은 pandas가 dask보다 더 빠르다고 할 수 있다. dataframe의 head만 보는데 밀리세컨드가 걸리는 것은 분석가 입장에서는 사용할 수 없는 수준의 속도이기 때문에다.
- 데이터프레임 groupby 연산
이미 head() 연산으로 pandas의 연산 속도가 더 빠르다는 것을 확인했지만, 실제 자주 사용하는 데이터프레임 연산 함수인 groupby()의 속도를 비교해보자.
timeit -r 2 -n 1 pd_df.groupby(['cat_1','cat_2','cat_3']).rid.count()
# 2.8 s ± 131 ms per loop (mean ± std. dev. of 2 runs, 1 loop each)
timeit -r 2 -n 1 dd_df.groupby(['cat_1','cat_2','cat_3']).rid.count().compute()
# 29.5 s ± 28.5 ms per loop (mean ± std. dev. of 2 runs, 1 loop each)
dask의 연산은 왜 이렇게 느린것인가? 혹시 내가 dask의 병렬 연산을 제대로 못사용하는 것은 아닐까?
Furthermore…
이어서 공부할 사항이 있다면?
kuberneteswithAWSmodin,vasx,koalas패키지
reference
process&thread best explanation